功能教程:全栈硬件健康感知平台 (Nexus Monitor)
本模块是 DeplOS 的 AIOps 智能运维大脑。有别于传统的基于简单阈值(如 CPU 利用率、硬盘剩余空间)的监控系统,Nexus Monitor 深度沉淀了国内头部互联网大厂超十万台服务器规模的硬件故障特征库。通过带外探针与 OS 内核层级的混合采集,系统能精准捕获底层的微观电气错误,在引发业务雪崩前进行毫秒级的故障定界与自愈预警。
工业级故障诊断与感知矩阵 (Fault Perception Matrix)
系统内置了跨平台(Linux / Windows)与跨架构(x86_64 / ARM64)的底层探针,支持以下核心子系统的深度异常诊断:
| 诊断域 (Domain) | 专家级故障感知能力 (Expert Level Perception) |
|---|---|
| 算力与总线诊断 | CPU MCE (Machine Check Exception): 动态捕获 CPU 内部硬件错误,结合微码版本精准区分是偶发性宇宙射线翻转还是硅晶体物理老化。 PCIe AER (Advanced Error Reporting): 透视 PCIe 链路层的不稳定,提前发现阵列卡或网卡掉盘前兆。 |
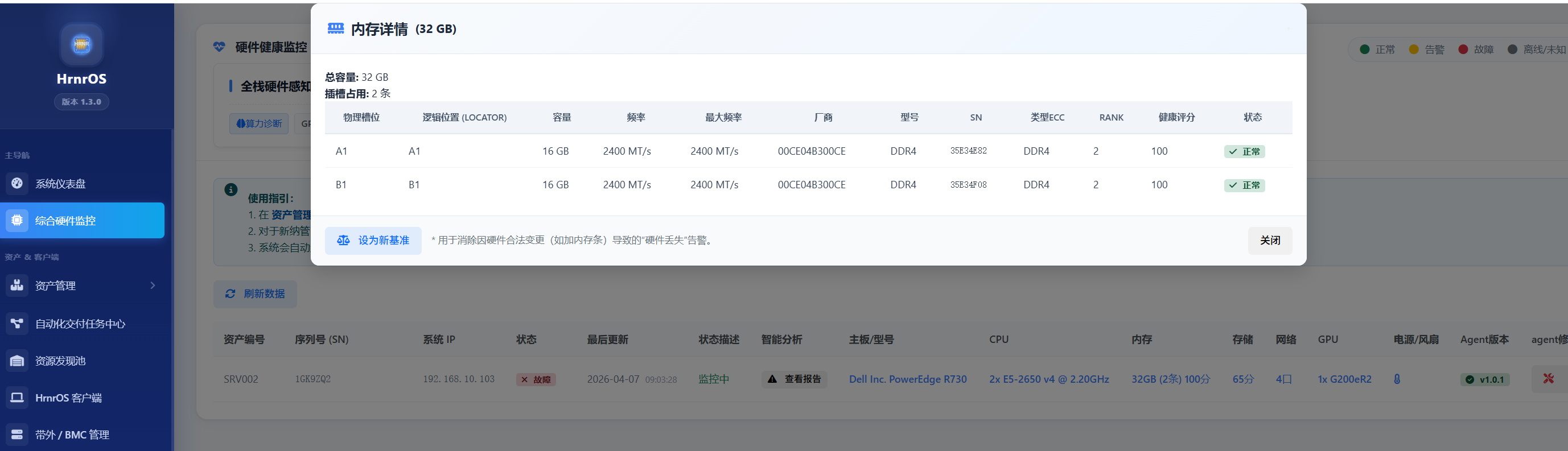
| 内存健康 (Memory) | CE/UCE 漏斗分析: 不仅统计内存纠错码(ECC)的可纠正错误 (CE) 与不可纠正错误 (UCE),更能通过大厂故障库算法,精准定位到具体内存条(如 DIMM A1),预测其“爆雷”概率。 |
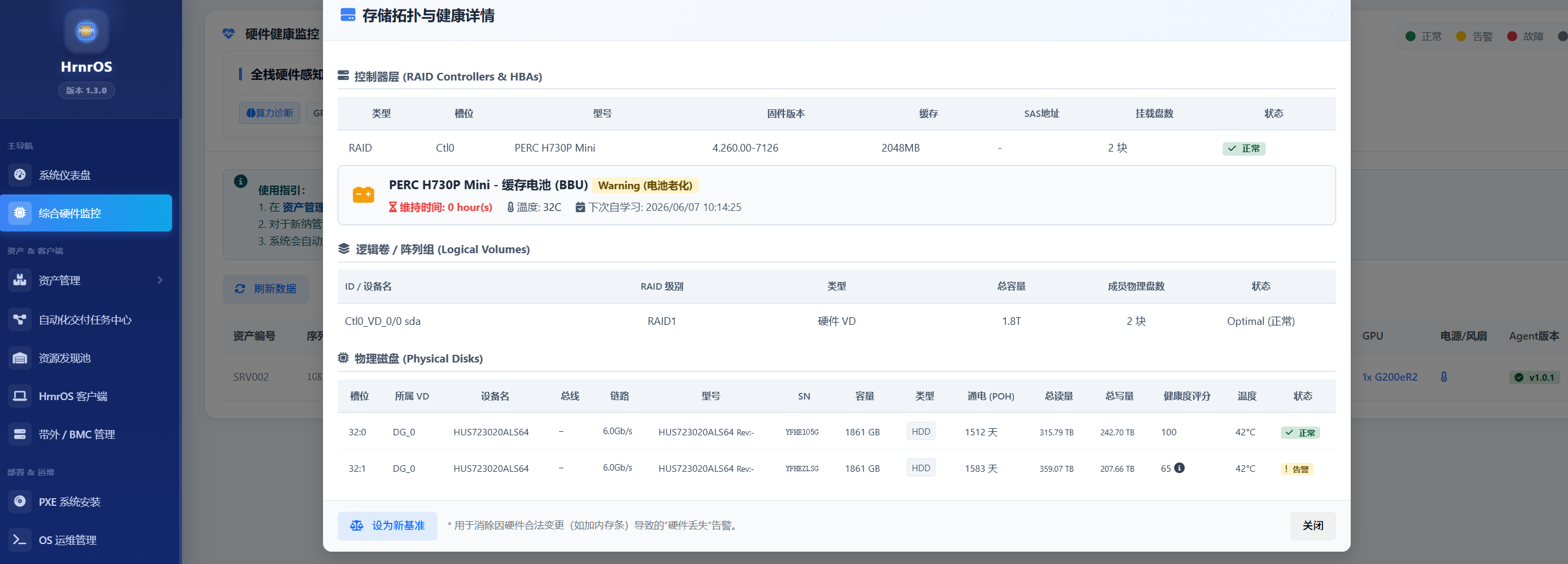
| 存储寿命预测 | NVMe S.M.A.R.T 深度巡检: 实时监控固态硬盘的写入放大率与可用备用块(Available Spare)。在 SSD 进入只读模式(Read-Only)或彻底掉速前,提前触发退役预警。 |
| GPU 状态跟踪 | HBM/ECC 显存监控: 针对 AI 算力集群,实时监控高带宽显存(HBM)的物理错误率,防范大模型训练中途因 GPU 显存故障导致的 Checkpoint 崩溃。 |
| 链路诊断 | 网卡底层丢包分析: 绕开系统协议栈,直接在网卡驱动层抓取 Tx/Rx 物理层错包(CRC Errors),精准判定是光模块衰减还是交换机端口协商问题。 |
⚠️ 关键前置:探针环境与基线策略
要激活全维度的感知能力,请确保目标资产池的服务器满足以下条件:
- 探针存活: 目标物理机操作系统内必须已安装并运行 DeplOS Agent。探针的存活状态会直接决定数据采集的连通性。
- 大厂规则库同步: 系统会定期从云端故障库拉取最新的硬件错误特征签名(Feature Signatures)。请确保控制节点具有访问同步源的网络权限,以保证诊断逻辑的时效性。
步骤 1: 监控大盘与全栈聚合感知
进入 [硬件健康监控] 页面,系统为您提供了“上帝视角”的资产聚合看板。
- 标签云与聚合分析:
- 页面顶部会直观展示当前纳管集群的架构占比(如 Linux/Windows,x86_64/ARM64)。
- 基于大厂经验,系统会将晦涩的报错提炼为直观的标签云 (Tag Cloud),如点击
<span class="tag-item">内存 CE/UCE</span>,即可一键过滤出所有存在内存隐患的节点。
- 健康度红绿灯体系:
- 资产列表采用严格的降级显示逻辑。任何一项子系统的非致命报错(如磁盘寿命降至 15%)会将节点标记为
Warning;而触发故障库红线(如连续发生 PCIe AER 致命报错)则直接标记为Critical,建议立即隔离。
- 资产列表采用严格的降级显示逻辑。任何一项子系统的非致命报错(如磁盘寿命降至 15%)会将节点标记为
步骤 2: 底层硬件诊断下钻 (Drill-down)
对于产生告警的节点,拒绝“盲人摸象”,直接透视底层。
打开硬件详情:
- 在资产列表中,点击相关告警模块旁的 “ 详情” 链接。
- 系统将调起沉浸式的
hw-modal硬件详情模态框。
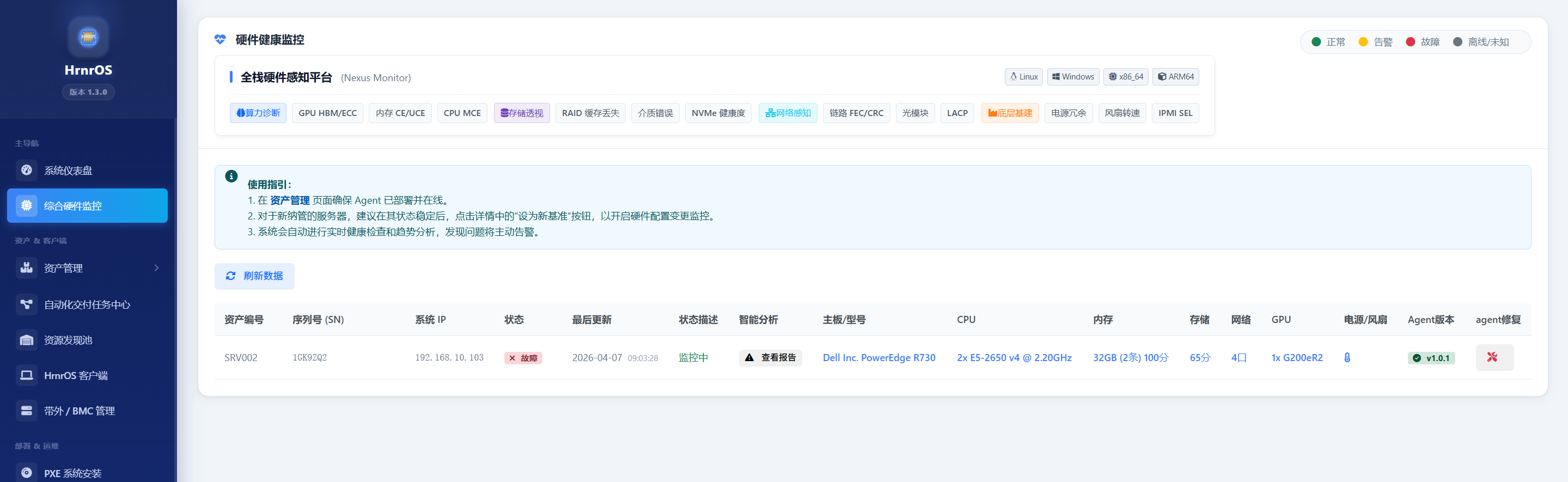
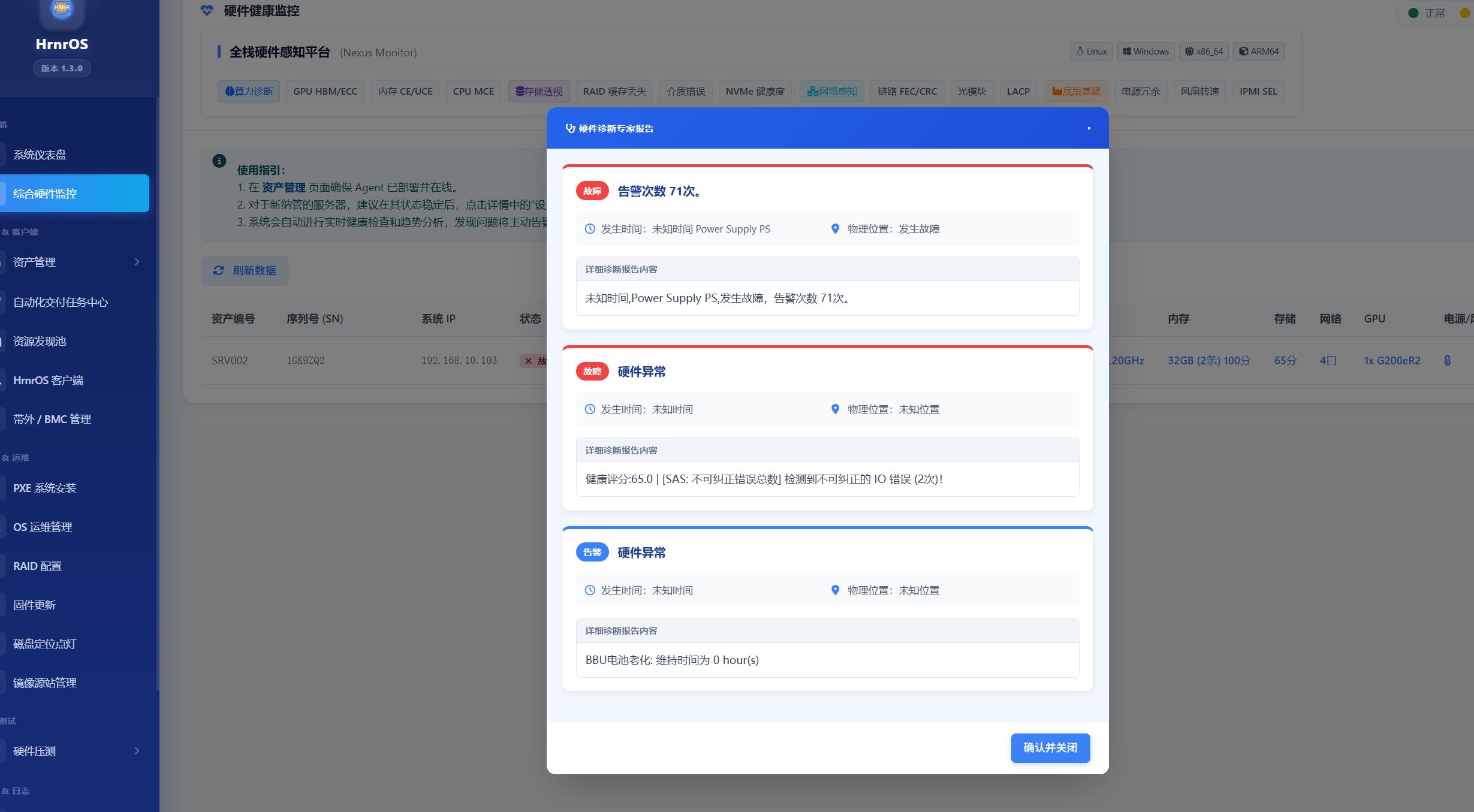
查看大厂经验判定:
- 这里不仅罗列当前的温度或转速,更会直接输出基于故障库的根因分析结论 (Root Cause Analysis)。
- 例如:传统 Zabbix 仅报“系统日志有 Error”,而 DeplOS 会提示“检测到 CPU 1 Node 0 存在频繁 MCE 报错,匹配到 Intel 微码 Bug 库,建议升级 BIOS,或更换对应 CPU”。
步骤 3: 探针生命周期与热升级 (Hot Upgrade)
随着故障库的迭代,底层的监控 Agent 也需要持续进化。本模块提供了平滑的无感升级机制。
- 识别版本差异: 列表中会明确标注 Agent 的当前版本。当有新版本探针可用时,可点击操作列的 “升级” 按钮。
- 执行热升级:
- 系统将弹出升级确认框。
- 点击 “确认升级” 后,右侧会展示进度轨道(Progress Track)。系统通过后端通道静默下发二进制文件并执行热替换。
- 业务无感保证: 整个重启耗时约 3-5 秒,对宿主机上运行的业务(如数据库、容器)没有任何网络或 IO 层面的影响。
- 实时日志追踪: 复杂的部署过程,您可以通过点击
deploy-log-modal(部署日志视图)来实时观察后端的通信回显。
步骤 4: 故障自愈与基线重置 (Intelligent Recovery)
当硬件故障已由驻场工程师物理修复(例如拔插更换了报警的内存条)后,需要在系统中消除记录。
- 智能修复下发 (Recover):
- 针对可软件干预的软故障(如重置网卡驱动、清除 BMC 历史告警),可点击 “智能修复”。系统将尝试下发修复脚本自动复位硬件状态。
- 重置健康基线 (Reset Baseline):
- 当确认硬件已被物理更换后,点击顶部的 “ 重置基线”。
- 系统将清空当前节点的历史报错累积计数,重新抓取全新的硬件特征作为健康起点,避免历史 CE/UCE 计数干扰新硬件的评估体系。